New Journal paper accepted for publishing in the Journal of “Multimedia Tools and Applications“.
The paper title is “A Framework for Automatic Semantic Video Annotation utilising Similarity and Commonsense Knowledgebases”
Abstract:
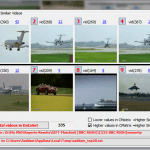
The rapidly increasing quantity of publicly available videos has driven research into developing automatic tools for indexing, rating, searching and retrieval. Textual semantic representations, such as tagging, labelling and annotation, are often important factors in the process of indexing any video, because of their user-friendly way of representing the semantics appropriate for search and retrieval. Ideally, this annotation should be inspired by the human cognitive way of perceiving and of describing videos. The difference between the low-level visual contents and the corresponding human perception is referred to as the ‘semantic gap’. Tackling this gap is even harder in the case of unconstrained videos, mainly due to the lack of any previous information about the analyzed video on the one hand, and the huge amount of generic knowledge required on the other.
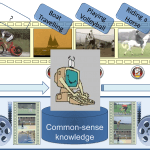
This paper introduces a framework for the Automatic Semantic Annotation of unconstrained videos. The proposed framework utilizes two non-domain-specific layers: low-level visual similarity matching, and an annotation analysis that employs commonsense knowledgebases. Commonsense ontology is created by incorporating multiple-structured semantic relationships. Experiments and black-box tests are carried out on standard video databases for
action recognition and video information retrieval. White-box tests examine the performance of the individual intermediate layers of the framework, and the evaluation of the results and the statistical analysis show that integrating visual similarity matching with commonsense semantic relationships provides an effective approach to automated video annotation.
Well done and congratulations to Amjad Altadmri .