Summary: “Object and Action Recognition Assisted by Computational Linguistics”.
The aim of this project is to investigate how computer vision methods such as object and
action recognition may be assisted by computational linguistic models, such as WordNet.
The main challenge of object and action recognition is the scalability of methods from
dealing with a dozen of categories (e.g. PASCAL VOC) to thousands of concepts (e.g.
ImageNet ILSVRC). This project is expected to contribute to the application of automated
visual content annotation and more widely to bridging the semantic gap between
computational approaches of vision and language.
Members of DCAPI have presented and showed their research work in the Annual Showcase Event for the School of Computer Science, University of Lincoln. (14th and 15th May). Saddam also won the “Best Demo” prize for his video matching & retrieval interactive demo.
Saddam receiving his “Certificate of Achievment” for “Best Demo”.
Saddam presenting his research work in Video Matching and retrieval.
Postgraduates by Research (PGRs) had all day on Wed 14th May and featured in the morning of Thursday 15th May as well, with visitors and companies representatives.
Saddam demonstrating his “Interactive, drag-n-drop Video matching and retrieval” demo to visitors & companies representatives and colleaguesAll around the poster, with explanation from Saddam on his work on the “Compressed Video matching and retrieval”
The event is organised by Dr Amr Ahmed (Leader of the DCAPI group, and the Program Leader for PGRs), for a number of years.
Annual “Showcase Event” for School of Computer Science. Dr Amr Ahmed take this intitiative and organised this event for a number of years.Amr is arranging the Registration and welcome table.
The event was also officially opened (and concluded) by the Head of School, Dr David Cobham, who attended the full program and handed the certificates to winners as well as the Helpers, including the Admin team.
Head of School, Dr David Cobham (left)Head of School handing in the “Thank You” Certificates for Helpers and the Admin Team.Head of School handing in the “Thank You” Certificates for Helpers and the Admin Team.
All had fun during the Poster session and inbetween the sessions as well.
PGRs together, with the Head of School and the Program Leader for PGRs, following the Posters session
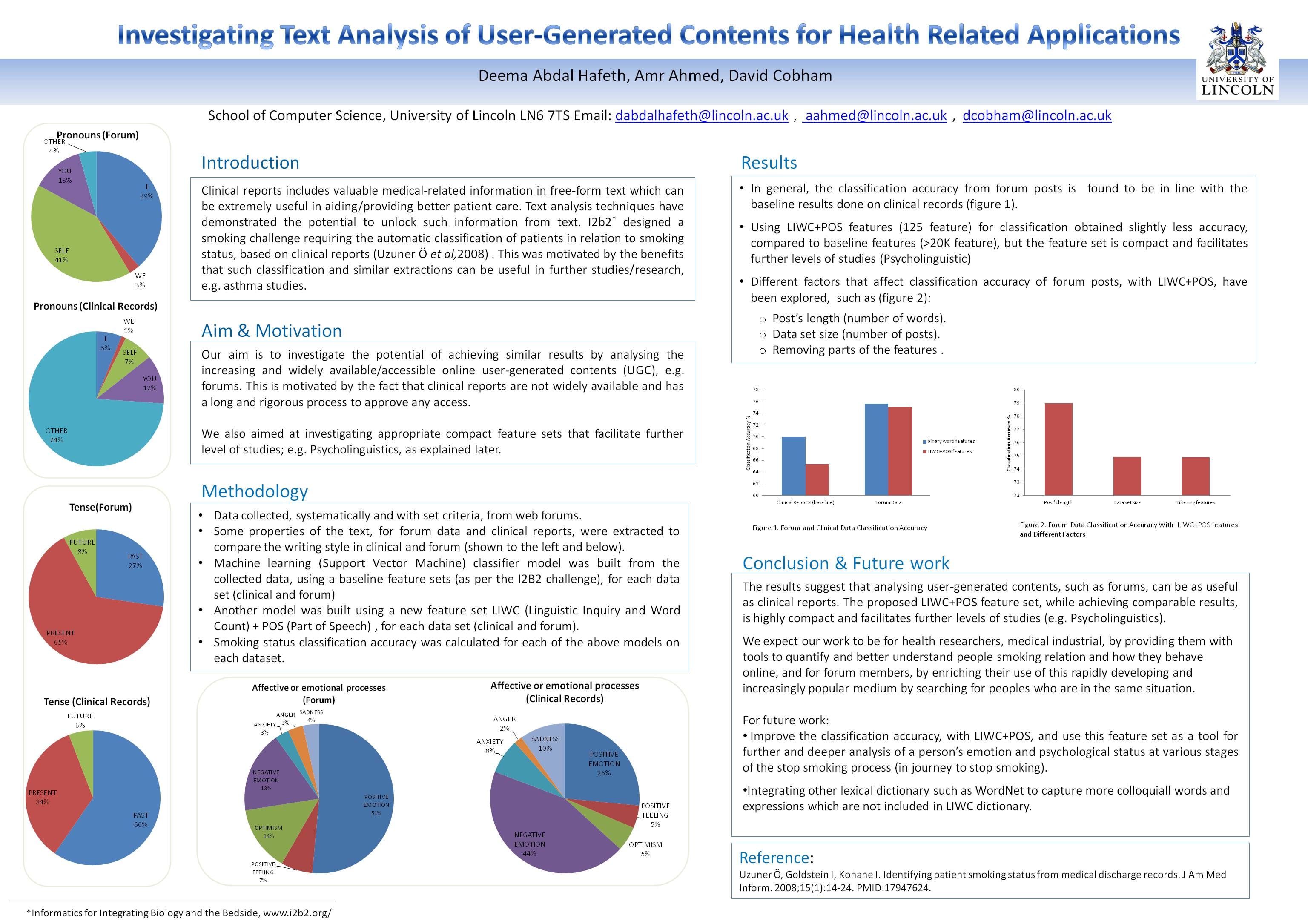
Clinical reports includes valuable medical-related information in free-form text which can be extremely useful in aiding/providing better patient care. Text analysis techniques have demonstrated the potential to unlock such information from text. I2b2* designed a smoking challenge requiring the automatic classification of patients in relation to smoking status, based on clinical reports (Uzuner Ö et al,2008) . This was motivated by the benefits that such classification and similar extractions can be useful in further studies/research, e.g. asthma studies.
Aim & Motivation
Our aim is to investigate the potential of achieving similar results by analysing the increasing and widely available/accessible online user-generated contents (UGC), e.g. forums. This is motivated by the fact that clinical reports are not widely available and has a long and rigorous process to approve any access.
We also aimed at investigating appropriate compact feature sets that facilitate further level of studies; e.g. Psycholinguistics, as explained later.
Methodology
•Data collected, systematically and with set criteria, from web forums.
•Some properties of the text, for forum data and clinical reports, were extracted to compare the writing style in clinical and forum (shown to the left and below).
•Machine learning (Support Vector Machine) classifier model was built from the collected data, using a baseline feature sets (as per the I2B2 challenge), for each data set (clinical and forum)
•Another model was built using a new feature set LIWC (Linguistic Inquiry and Word Count) + POS (Part of Speech) , for each data set (clinical and forum).
•Smoking status classification accuracy was calculated for each of the above models on each dataset.
Results
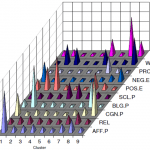
•In general, the classification accuracy from forum posts is found to be in line with the baseline results done on clinical records (figure 1).
•
•Using LIWC+POS features (125 feature) for classification obtained slightly less accuracy, compared to baseline features (>20K feature), but the feature set is compact and facilitates further levels of studies (Psycholinguistic)
•
•Different factors that affect classification accuracy of forum posts, with LIWC+POS, have been explored, such as (figure 2):
o Post’s length (number of words).
o Data set size (number of posts).
o Removing parts of the features .
Conclusion & Future work
The results suggest that analysing user-generated contents, such as forums, can be as useful as clinical reports. The proposed LIWC+POS feature set, while achieving comparable results, is highly compact and facilitates further levels of studies (e.g. Psycholinguistics).
We expect our work to be for health researchers, medical industrial, by providing them with tools to quantify and better understand people smoking relation and how they behave online, and for forum members, by enriching their use of this rapidly developing and increasingly popular medium by searching for peoples who are in the same situation.
For future work:
• Improve the classification accuracy, with LIWC+POS, and use this feature set as a tool for further and deeper analysis of a person’s emotion and psychological status at various stages of the stop smoking process (in journey to stop smoking).
•Integrating other lexical dictionary such as WordNet to capture more colloquiall words and expressions which are not included in LIWC dictionary.
Reference:
Uzuner Ö, Goldstein I, Kohane I. Identifying patient smoking status from medical discharge records. J Am Med Inform. 2008;15(1):14-24. PMID:17947624.
Interested in joining us as a “Research Fellow”?
Get in touch by emailing aahmed@lincoln.ac.uk
Welcome to the DCAPI research group.
Our multi-disciplinary research is mainly focused on the analysis and mining of digital contents (Visual; images and videos, and textual). This includes Computer Vision, Image/Video Processing and analysis, Semantic Analysis, annotation, Action recognition, Image/Video Matching and similarity (Copy & Near-Duplicate detection), and many others.
We welcome any discussion and potential collaboration. Please get in touch with us (contacts on the right side-bar).
Amjad Altadmri has passed his PhD viva, subject to minor amendments, earlier today.
Thesis Title: “Semantic Video Annotation in Domain-Independent Videos Utilising Similarity and Commonsense Knowledgebases”
Thanks to the external, Dr John Wood from the University of Essex, the internal Dr Bashir Al-Diri and the viva chair, Dr Kun Guo.
Congratulations and Well done.
All colleagues are invited to join Amjad on celebrating his achievement, tomorrow (Thursday 28th Feb) at 12:00noon, in our meeting room MC3108, with some drinks and light refreshments available.
New Journal paper accepted for publishing in the Journal of “Multimedia Tools and Applications“.
The paper title is “A Framework for Automatic Semantic Video Annotation utilising Similarity and Commonsense Knowledgebases”
Abstract:
The rapidly increasing quantity of publicly available videos has driven research into developing automatic tools for indexing, rating, searching and retrieval. Textual semantic representations, such as tagging, labelling and annotation, are often important factors in the process of indexing any video, because of their user-friendly way of representing the semantics appropriate for search and retrieval. Ideally, this annotation should be inspired by the human cognitive way of perceiving and of describing videos. The difference between the low-level visual contents and the corresponding human perception is referred to as the ‘semantic gap’. Tackling this gap is even harder in the case of unconstrained videos, mainly due to the lack of any previous information about the analyzed video on the one hand, and the huge amount of generic knowledge required on the other.
This paper introduces a framework for the Automatic Semantic Annotation of unconstrained videos. The proposed framework utilizes two non-domain-specific layers: low-level visual similarity matching, and an annotation analysis that employs commonsense knowledgebases. Commonsense ontology is created by incorporating multiple-structured semantic relationships. Experiments and black-box tests are carried out on standard video databases for
action recognition and video information retrieval. White-box tests examine the performance of the individual intermediate layers of the framework, and the evaluation of the results and the statistical analysis show that integrating visual similarity matching with commonsense semantic relationships provides an effective approach to automated video annotation.
Three members of the Lincoln School of Computer Science, and the DCAPI group, have attended the Vision & Language (V&L) Network workshop, 13-14th Dec. 2012 in Sheffield, UK.
Amr Ahmed, Amjad Al-tadmri and Deema AbdalHafeth attended the event, where Amjad and Deema delivered 2 oral presentations and 2 posters about their research work:
1. VisualNet: Semantic Commonsense Knowledgebase for Visual Applications
2.Investigating text analysis of user-generated contents for health related applications
Amr Ahmed attended the ECM (Executive Committee Meeting) of his SUS-IT project (http://sus-it.lboro.ac.uk/) at Loughborough, and participated in the 2 days workshop for the project. This is one of the very important meetings, especially towards the late stage of the project, with all workpackages represented.